Humanoid World Model
An open-source world model for humanoid robots.
Masked Transformer
Generated

Ground Truth

Generated

Ground Truth

Generated

Ground Truth

Generated

Ground Truth

Flow Matching
Generated

Ground Truth

Generated

Ground Truth

Generated

Ground Truth

Generated

Ground Truth

We present Humanoid World Models (HWM) 🤖🧠 — a family of lightweight, open-source video prediction models for humanoid robots — showcased at the ICML 2025 Workshop on Physically Plausible World Models. The model predicts 8 future video frames conditioned on 9 past video frames and humanoid control tokens (e.g., joint angles, velocities).
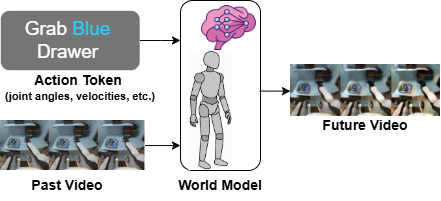
Motivation
World foundation models can predict high fidelity and physically plausible future video conditioned on the past. Such world models can substantially help the development of humanoid robots. In particular, world models can help evaluate humanoid policies, generate synthetic training data, learn general-purpose representations, and help conduct long-horizon planning. However, many world foundation models are closed-source and/or require large amounts of computational resources to run (e.g. 8+ H100s).
Key Features:
- Two model families: While Masked-HWM achieves higher visual fidelity and faster inference, Flow-HWM offers benefits in continuous latent modeling. Our findings favor Masked-HWM for most practical deployments:
- Masked-HWM: non-autoregressive masked video transformer using VQ-VAE latents.
- Flow-HWM: continuous VAE latent space model using flow-matching.
- Architecture Variants: Various attention styles (joint vs. split attention) and weight-sharing strategies were explored, providing up to 53% parameter reduction with minimal performance degradation.
- Efficiency: Trained 3 Nvida A6000 GPUs.
- Data: Trained on 100+ hours of egocentric humanoid video and control traces from the 1xGPT dataset.
Architecture Diagrams
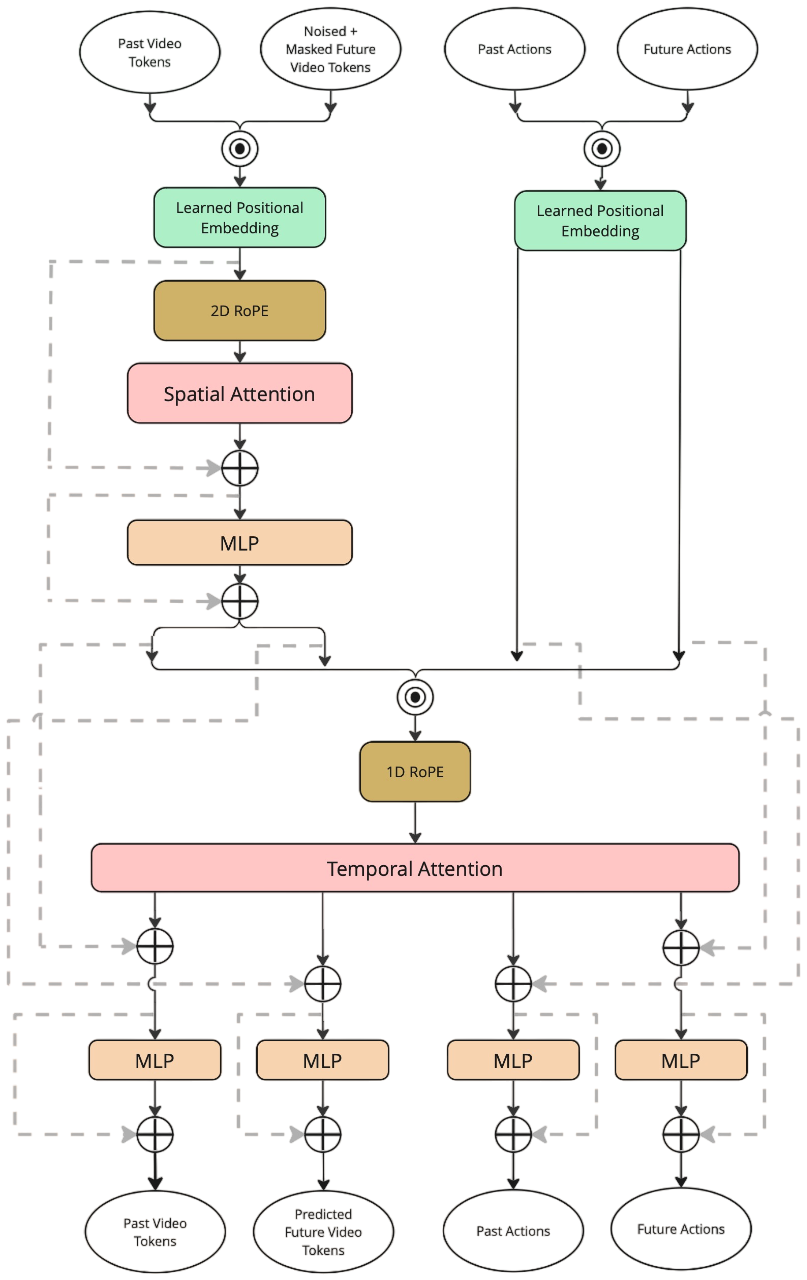
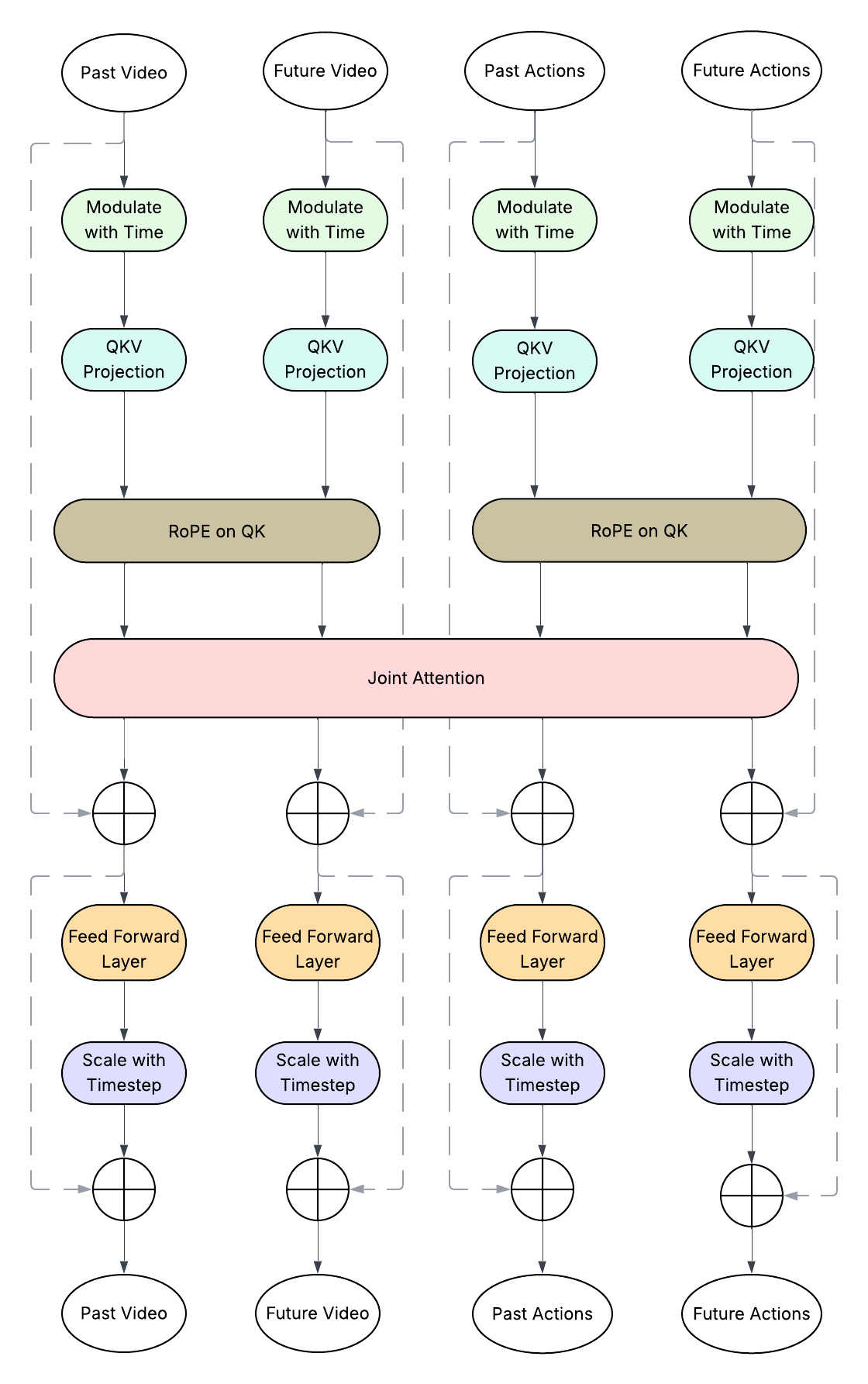
Quantitative Performance
| Model Variant | FID ↓ | PSNR ↑ | Params (B) | Samples/sec |
|---|---|---|---|---|
| Masked-HWM (Base) | 10.13 | 29.02 dB | 0.321 | 2.27 |
| Masked-HWM (Full Sharing) | 14.21 | 28.66 dB | 0.195 | 2.36 |
| Flow-HWM (Base) | 111.59 | 20.42 dB | 1.36 | 1.69 |
| Flow-HWM (Full Sharing) | 110.73 | 20.43 dB | 0.648 | 1.91 |
Code
Citation
If you use this work, please cite our ICML workshop paper:
Ali, Q., Sridhar, A., Matiana, S., Wong, A., & Al-Sharman, M. (2025). Humanoid World Models: Open World Foundation Models for Humanoid Robotics. ICML Workshop on Physically Plausible World Models.
For code, data, or collaboration inquiries, contact Qasim Ali.
References
1X Technologies. (2024). 1X World Model Challenge (Version 1.1) [Data set].